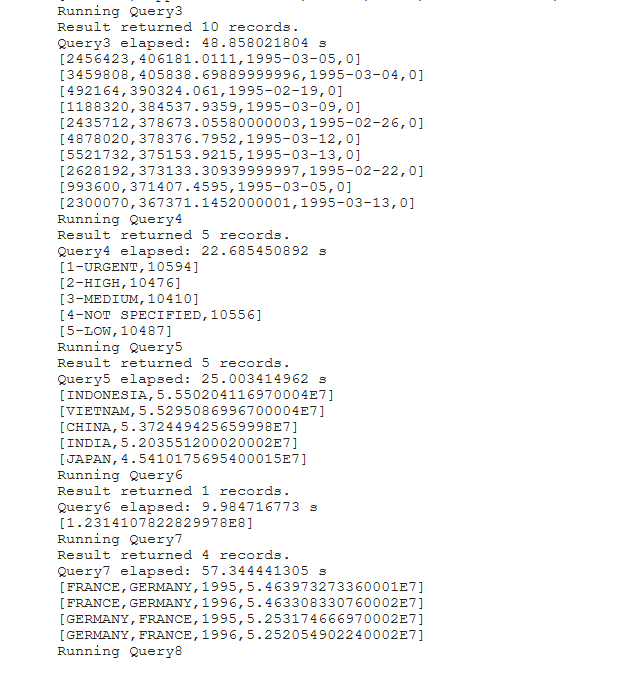
Running the TPC-H Benchmarks
The TPC-H is a decision support benchmark. It consists of a suite of business oriented ad-hoc queries and concurrent data modifications. The queries and the data populating the database have been chosen to have broad industry-wide relevance. This benchmark illustrates decision support systems that examine large volumes of data, execute queries with a high degree of complexity, and give answers to critical business questions. The performance metric reported by TPC-H is called the TPC-H Composite Query-per-Hour Performance Metric (QphH@Size), and reflects multiple aspects of the capability of the system to process queries. These aspects include the selected database size against which the queries are executed, the query processing power when queries are submitted by a single stream, and the query throughput when queries are submitted by multiple concurrent users.
Running the TPC-H Benchmarks in Spark Cyclone
We have provided the layout for you to tryout the benchmarks in our repo.
# Generate the data
$ cd Spark Cyclone/tests/tpchbenchmark/dbgen
$ make
# Move the data to hadoop
$ cd Spark Cyclone/tests/tpchbenchmark/
$ /opt/hadoop/bin/hdfs dfs -put dbgen
$ run_ve.sh
You can observe the job in Hadoop:

Sample of Job Running in Node: